本文共 4934 字,大约阅读时间需要 16 分钟。
作者介绍:Matthew Emery,加拿大数据科学家,RAP爱好者,毕业于英属哥伦比亚大学。

Email:m.emery@alumni.ubc.ca
LinkedIn:https://www.linkedin.com/in/lstmemery
GitHub:https://github.com/lstmemery
在数据科学领域有一个叫做“没有免费的午餐”定理,具体来说就是,对于任意两个算法,当它们在面对所有可能的问题时的表现被平均化后,这两个算法是等价的,如果这个定理成立,那为什么2015年在数据科学竞赛网站Kaggle上赢得比赛的绝大部分方案都采用了XGBoost呢?XGBoost是如何工作的呢?它运行起来又像什么呢?
本文打算回答这些问题,注意,对你而言,不一定需要精通数学,但需要知道决策树是怎么一回事。
梯度提升树(Gradient Boosted Trees,GBT)科普
过度拟合相当于填鸭式的机器学习,如果你只知其然而不知其所以然,你就难以得到想要的结果,决策树就是典型的例子,因此,数据科学家必须学习多门技术,从而避免过度拟合的出现。
其中一个方法就是boosting(提升算法),我们通过训练几个弱分类器(低度拟合决策树)代替训练一个强分类器(过度拟合决策树),其中的诀窍就是让当前的树了解前面哪一颗树有错误,为了让boosting工作起来,需要用不同的方法让分类器处于错误状态,训练结束后,每棵树都要确定每个样本的分类,通过这种方式,部分分类器的弱点可以得到其它分类器的补偿。
自适应提升算法(Adaptive boosting ,AdaBoost)是boosting最经典的实现方法,第一棵树和其它分类错误的树完全一样,后面的树也和前面的树一样,被粗暴地认为分类 错误,这种策略导致在新建一棵树时要优先考虑正确的分类。
迭代提升算法(Gradient boosting)是boosting另一种优秀实现,第一棵树用常规方法拟合了数据,后面的树会尝试找出将前面的树的错误减少到最小的判定方式,如果我们知道描述数据的数学函数,要将错误减少到最小就很好办,我们就不会用决策树来尝试接近它。在不知道这个函数的情况下,我们需要一个新的策略来将错误减少到最小。
假设你在大雾笼罩的山顶,伸手不见五指,要找到下山最快的道路,哪种方法是最可行的?一种方法是伸出你的脚在每个方向上都试探一下,从而感知到下山最陡峭的路,现在,沿着这条最陡峭的路下山,不断重复这个过程,直到你下到山脚,数据科学家把这个算法叫做梯度下降算法,在本文中,我们也称之为梯度提升树算法。
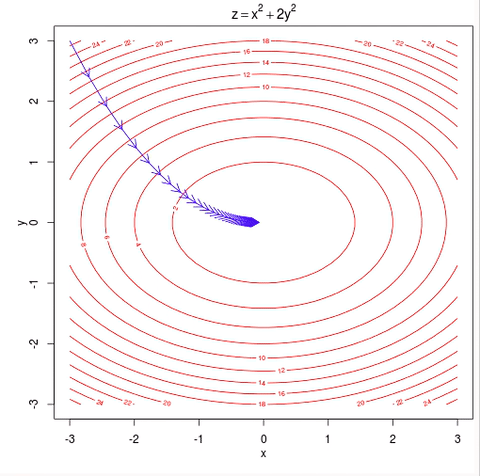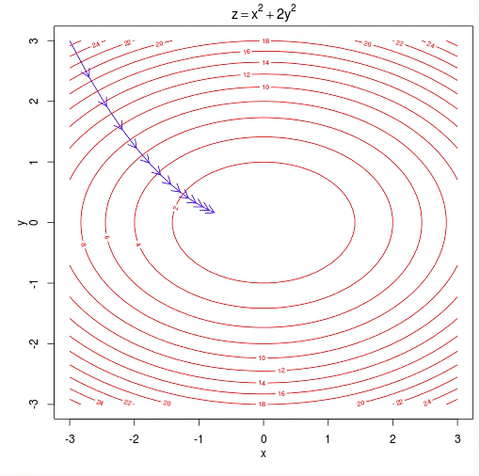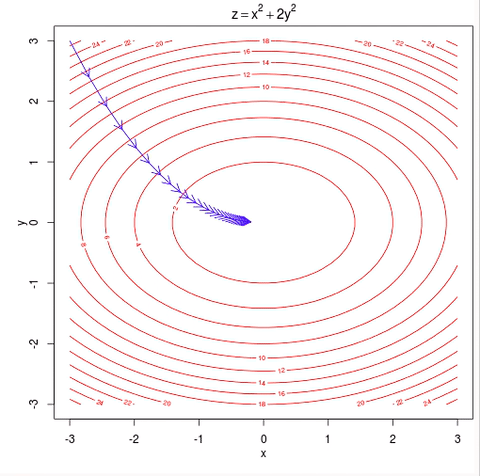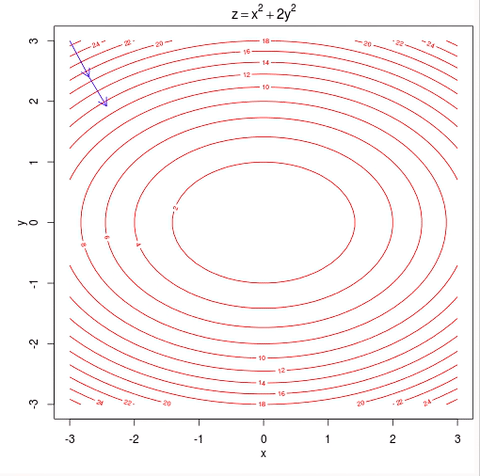
梯度下降算法示例
是什么让XGBoost如此受欢迎?
梯度提升树算法最早公开的时间是2001年,那么XGBoost究竟是怎么改进这个算法的呢?
我经常看到有人误解XGBoost的精度要比其它梯度提升树算法实现精度高,可事实不是这样,算法的作者发现XGBoost的错误率和SCI-Kit Learn实现几乎一样。
XGBoost不是绝对的精确,但它绝对够快:
1、XGBoost识别能力不强:提升树特别适合特征明确的场景(如这个人出生在英格兰吗?),但在真实数据集中,特征明确的列通常是0,在决定从哪里分类时,XGBoost有非零数据的指针,只需要查找这些记录即可。
2、XGBoost可并行:提升树算法最消耗时间片的是对连续型特征排序(如你每天开车上班有多远?),稀疏数据结构和聪明的实现方式让XGBoost可为每个列独立排序,通过这种方法,排序工作在CPU的并行线程之间可以分离执行。
3、XGBoost支持近似分类:为了在连续型特征上找到最佳分类点,梯度提升树需要将所有数据放入内存进行排序,对小数据集来说不会存在什么问题,但当数据集大小超过内存时这个方法就行不通了,XGBoost可以对这些数据使用容器进行粗糙排序而不是完整排序,XGBoost论文作者表示,只要容器数量足够多,分类表现可以接近于精确分类。
举个栗子
我们还是举个例子来看看XGBoost到底可以做什么,这里我以一个房产数据集作为训练数据,可以从下载。
from sklearn.model_selection import train_test_splitimport xgboost as xgbimport pandas as pdfrom sklearn.ensemble import GradientBoostingRegressor, \ AdaBoostRegressor, RandomForestRegressorX = pd.read_csv('../../results/munged_training.csv')y = pd.read_csv('../../results/munged_labels.csv')# Make a validation setX_train, X_validation, y_train, y_validation = train_test_split(X, y, random_state=1848) # Sci-Kit Learn's Out of the Box Gradient Tree Implementationsklearn_boost = GradientBoostingRegressor(random_state=1849)sklearn_boost.fit(X_train, y_train.values.ravel())print('Training Error: {:.3f}'.format(1 - sklearn_boost.score(X_train, y_train)))print('Validation Error: {:.3f}'.format(1 - sklearn_boost.score(X_validation, y_validation)))%timeit sklearn_boost.fit(X_train, y_train.values.ravel()) Training Error: 0.031Validation Error: 0.1101 loop, best of 3: 1.23 s per loop
# XGBoostxgb_boost = xgb.XGBRegressor(seed=1850)xgb_boost.fit(X_train, y_train.values.ravel())print('Training Error: {:.3f}'.format(1 - xgb_boost.score(X_train, y_train)))print('Validation Error: {:.3f}'.format(1 - xgb_boost.score(X_validation, y_validation)))%timeit xgb_boost.fit(X_train, y_train.values.ravel()) Training Error: 0.038Validation Error: 0.1111 loop, best of 3: 443 ms per loop
# Sci-Kit Learn's Adaptive Boostingada_boost = AdaBoostRegressor(random_state=1851)ada_boost.fit(X_train, y_train.values.ravel())print('Training Error: {:.3f}'.format(1 - ada_boost.score(X_train, y_train)))print('Validation Error: {:.3f}'.format(1 - ada_boost.score(X_validation, y_validation)))%timeit ada_boost.fit(X_train, y_train.values.ravel()) Training Error: 0.126Validation Error: 0.1961 loop, best of 3: 729 ms per loop
# Random Forest: A fast, non-boosting algorithmrandom_forest = RandomForestRegressor(random_state=1852)random_forest.fit(X_train, y_train.values.ravel())print('Training Error: {:.3f}'.format(1 - random_forest.score(X_train, y_train)))print('Validation Error: {:.3f}'.format(1 - random_forest.score(X_validation, y_validation)))%timeit random_forest.fit(X_train, y_train.values.ravel()) Training Error: 0.024Validation Error: 0.1281 loop, best of 3: 398 ms per loop
首先,我们来看看合法性错误,实现和XGBoost实现几乎是一样的,它们两者使用默认的超参数就打败了AdaBoost(自适应提升算法)和RandomForest(随机森林算法),但XGBoost在执行速度上的优势非常明显,相当于Sci-Kit Learn实现的3倍,速度和随机森林算法相当。
XGBoost的准确性和速度让它成为评估特征工程的一个出色工具,你也可以加入新特征来给XGBoost交错旋转提速,交叉验证并查看新特征是否提升了模型的准确性,因为提升树是支持过度拟合的,你可以不断地加入新的特征,直到想不到新的特征为止。
XGBoost并不是到处都在使用,这也许就是最好的(虽然它在大多数情况下表现都非常佳),但它又可到处使用,只要是围绕数据开展探索,XGBoost无疑是你的最佳拍档。
以上为译文
文章原标题《Why Kagglers Love XGBoost 》,作者Matthew Emery,译者:耕牛的人,审校:主题曲(身行)
文章为简译,更为详细的内容,请查看
转载地址:http://qzzxa.baihongyu.com/